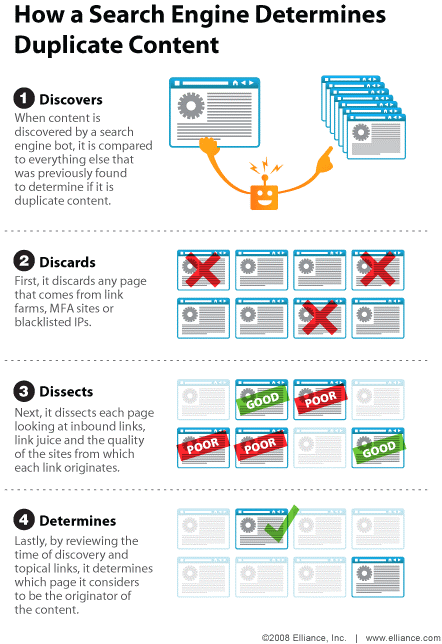
Torno anche oggi a parlare di contenuti duplicati, con questa bella immagine che illustra in 4 punti (Discovers, Discards, Dissects e Determines) il processo con cui il motore di ricerca discrimina un contenuto originale (rispetto a quello duplicato).
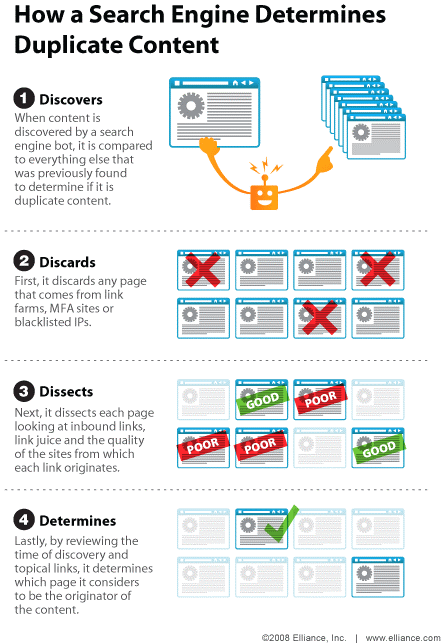
Eccovi (tradotte in italiano) le 4 operazioni che esegue il search engine:
- Scoprire Quando il bot del motore di ricerca scopre un nuovo contenuto, lo compara con gli altri materiali già in suo possesso, per determinare se è duplicato o meno.
- Scartare Inizialmente, elimina tutte le pagine provenienti da link farm, siti MFA (Made For AdSense) e indirizzi IP blacklistati.
- Separare Successivamente, divide fra “buone e cattive” le singole pagine in base agli inbound link, al link juice e alla qualità dei siti dai quali provengono i link.
- Determinare Infine, esaminando l’anzianità del documento e la tipologia dei link (=se sono attuali o meno), determina la pagina che può essere considerata come “generatore” del contenuto (ovvero l’originale).
Fonte: How A Search Engine Determines Duplicate Content