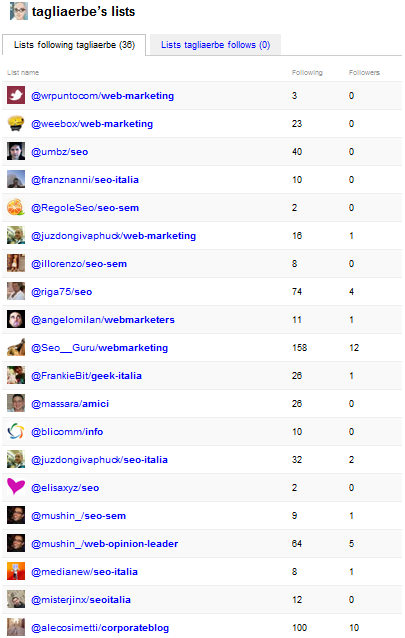
Chi utilizza Twitter in modo un pò più approfondito e interessato del sottoscritto (ci vuol poco, in effetti…), avrà notato che da qualche giorno è comparsa una nuova feature, che è riuscita a colpire anche ad un anti-micro-blogger come me: sto parlando delle liste. Donatella Plastino ne ha scritto una ottima analisi (ottimi pure i commenti) dal punto di vista “social”, alla quale c’è ben poco da aggiungere… io mi permetto di dire solamente due paroline sul lato “search”. Come verranno utilizzate le Twitter Lists in Google e Bing Qualche giorno fa analizzavo il nuovo trend dei 2 principali motori di ricerca, che da poco han deciso di integrare i cinguettii provenienti da Twitter. Ma inglobare un flusso scomposto di micro-messaggi, magari ordinati esclusivamente in base alla “freschezza” o al numero di follower, porterebbe alla generazione di SERP ben poco rilevanti: nell’alchimia ci vuole qualche elemento in più, elemento che potrebbe provenire proprio da una analisi fatta sulle liste. Mi spiego meglio con una immagine.
Qui sopra puoi vedere come, in pochi giorni, il TagliaTwitter sia finito all’interno di una quarantina di liste. Se noti, nella maggior parte di queste il nome ricalca in modo più o meno importante quello di cui parlo abitualmente: il mio account viene infatti identificato nell’ambito SEO/Web Marketing in più della metà dei casi. Come utizzare questi dati nelle SERP di Google e Bing? Semplicemente, associando all’account Twitter in questione uno o più tag, oltre ad un punteggio rilevanza determinato dal numero di follower/following dell’account (e della lista), nonchè dall’autorevolezza (e relativi tag) del twittatore e un pò di altri dati… ora spiego meglio 🙂 L’algoritmo della rilevanza di Twitter… ideato da me Ecco come procederei: 1. Innanzitutto, prenderei il numero di follower dell’account mettendolo in rapporto al numero di following: più i due numeri sono vicini l’uno all’altro, e più un account è in odore di spam (= flag negativo). 2. Una prima analisi incrociata va fatta proprio su follower e following: in base a questa rete di relazioni, eliminando il rumore di fondo (=spammer), si può già capire qualcosa circa la tipologia dei contatti dell’account. 3. A questo punto, occorre analizzare il contenuto, i link, gli hashtag e i followfriday del twittatore, in modo da capire di quali argomenti parla abitualmente e quali account consiglia (nel caso del followfriday); anche in questo caso, sarà necessario isolare/eliminare i tweet poco rilevanti, concentrandosi su quelli “di qualità”. 4. Ai dati di cui sopra, aggiungiamo ora quelli estrapolati dalle liste: prendiamo il nome dato alla lista, analizziamo gli altri account inseriti nella lista (per comprendere autorevolezza e affinità al tema trattato), e guardiamo anche il numero di iscritti alla lista e la qualità degli altri follower di quella lista. 5. Esempio: Matt Cutts ha oltre 40.000 follower e segue meno di 200 persone (quindi un account del genere va inserito fra quelli “trusted”). E quasi sicuramente i 200 account che segue (e/o che consiglia con i followfriday) sono di qualità. Se poi aggiungiamo che Cutts è inserito in oltre 1.500 liste, molte delle quali con nomi tipo “google” o “seo”, e che il suo account è incluso in liste seguitissime di personaggi a loro volta autorevoli (come, ad esempio, Scobleizer), il quadro è completo: i tweet di Matt Cutts dovranno sicuramente avere una rilevanza superiore a quelli di altri nelle SERP, quando si cerca per argomenti affini a Google o alla SEO. Penso che in Twitter abbiamo ragionato più o meno così, che ne dici? 🙂